Pintos, Priority Scheduling and Synchronization
CPU를 점유하는 과정을 추상화한 개념!
The preemption
CPU에서 현재 실행 중인 프로세스를 중단하고 실행할 다른 프로세스로 전환하는 운영체제 개념.
🔎 CPU 선점이 필요한 이유?
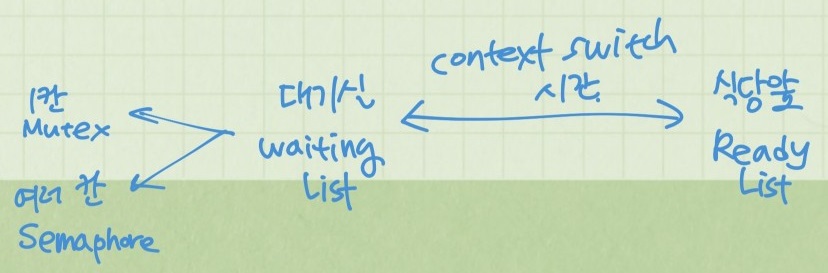
당연한 이야기지만, 이 모든 작업은 자원을 더욱 효율적으로 사용하기 위해서다.
프로세스를 선점하고 다른 프로세스가 실행되도록 허용하므로써 운영체제 리소스의 공정성과 효율성을 보장해준다.
waiting list에 있냐, read list에 있냐 이동하는데도 비용&시간이 소요되므로 상황을 잘 고려해 context swith를 할지 말지 정해줘야 한다.
대기실 칸이 한칸이면 Mutex, 여러칸이면 semaphore
Pintos 과제에서 thread_yield()함수가 context switch를 수행하는 함수이다.
📄 thread.c
/* Yields the CPU. The current thread is not put to sleep and
may be scheduled again immediately at the scheduler's whim. */
/* 나는 ready_list로, 지금 현재 thread를 running 상태로! */
void
thread_yield (void) {
struct thread *curr = thread_current ();
enum intr_level old_level;
ASSERT (!intr_context ());
old_level = intr_disable ();
if (curr != idle_thread)
/* 현재 thread가 CPU를 양보하여 ready_list에 삽입 될 때
우선순위 순서로 정렬되어 삽입되도록 수정 */
list_insert_ordered(&ready_list, &curr->elem, cmp_priority, NULL);
// list_push_back (&ready_list, &curr->elem);
do_schedule (THREAD_READY);
intr_set_level (old_level);
}lock
한정적인 공유자원은 누군가가 점유해 사용하고 있으면 다른 쓰레드가 사용할 수 없다.
그렇기 때문에 줄을 서야 한다.
내가 사용하고 싶은 공유자원을 누군가가 사용하고 있다. 그러면 나는 waiting list에서 lock를 살펴보며 대기하고 있는 것이다.
🔎 그러면 thread는 lock의 어떤 정보를 살펴보고 접근할까?

바로 lock value인 sema이다.
📄 synch.h
/* Lock. */
struct lock {
struct thread *holder; /* Thread holding lock (for debugging). */
struct semaphore semaphore; /* Binary semaphore controlling access. */
};
📄 synch.c
void
sema_init (struct semaphore *sema, unsigned value) {
ASSERT (sema != NULL);
sema->value = value;
list_init (&sema->waiters);
}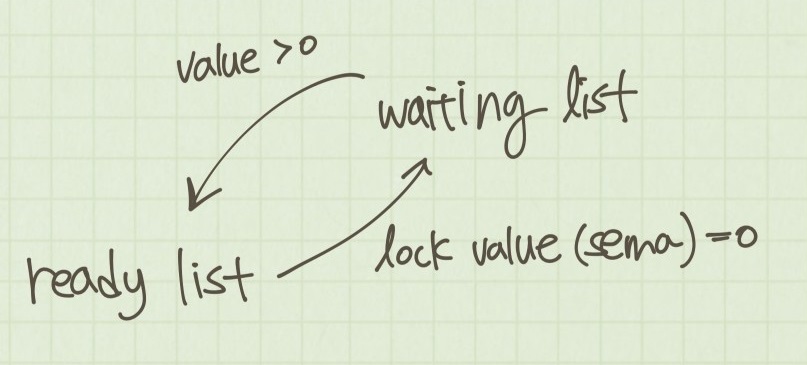
공유자원을 대기하고싶은 thread는 이 sema값을 살펴보면서 대기하고 있다가 접근할 수 있으면, 공유자원을 점유해 사용할 수 있는 것이다. sema값이 0이면 임계영역 내 모든 공유자원이 사용중이라는 의미이다.
sema값이 음수인 경우가 있을 수 있는데, 이 경우에는 그 절대값은 semaphore에서 대기하고 있는 프로세스 수를 의미한다. pintos과제 내에서는 sema값이 음수값이 나올 수 없게 설계 되어 있다.
lock이 풀리면 공유자원을 사용할 수 있게 되므로 공유자원에 접근해 점유하면된다!
🔎 동시성 제어 도구를 이용하더라도 thread 대기는 피할 수 없는건가?
Condition Variables 인 wait, signal, broadcast 연산도 busy waiting을 완전하게 제거하지 못했다는 것을 어느 정도 인정해야한다. 임계구역에만 국한되어 있기 때문에 busy waiting이 존재할 수 밖에 없다. 하지만 이러한 동시성 제어 도구(Lock, Semaphore, Condition variables)를 이용하면 공유자원의 임계구역(critical area)는 거의 항상 비어있으며 busy waiting은 드물게 발생, 발생하더라도 그 시간은 매우 짧기 때문에 효율적으로 자원을 제어할 수 있다.
FCFS
first come first serve
우선순위 스케줄링은 wait list의 맨앞에 우선순위가 가장 높은 대기 thread를 배치하므로써 리스트의 front값을 스케줄링 하는 방식이다.
📄 synch.c
void
cond_wait (struct condition *cond, struct lock *lock) {
...
/* condition variable의 waiters list에 우선순위 순서로 삽입되도록 수정 */
// list_push_back (&cond->waiters, &waiter.elem);
list_insert_ordered(&cond->waiters, &waiter.elem, cmp_sem_priority, NULL);
...
sema_down (&waiter.semaphore);
lock_acquire (lock);
}
📄 thread.c
/* 기존 라운드 로빈 RR, FIFO, 시분할 preemth */
static void
do_schedule(int status) {
...
while (!list_empty (&destruction_req)) {
struct thread *victim =
list_entry (list_pop_front (&destruction_req), struct thread, elem);
...
}
...
schedule ();
}
Priority Inversion
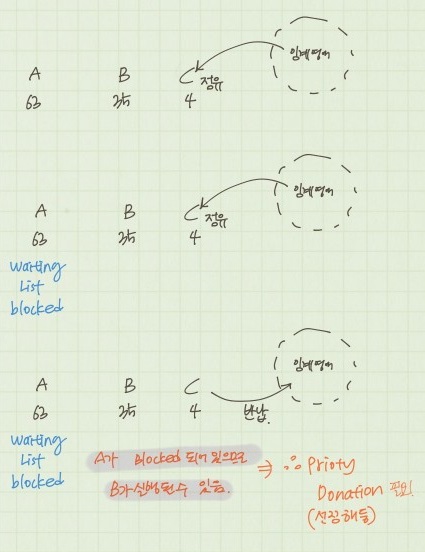
blocked 처리해 대기 리스트에 있으면 현재 공유자원을 점유하고 있는 thread(C, 4)의 우선순위가 대기하고 있는 thread의 우선순위(A, 63)보다 낮을 때 발생한다. 이럴 경우, C가 공유자원을 다 쓰고 lock을 해제할때 우선순위기가 A보다 낮은 B가 공유자원을 점유할 수 있어 우선순위가 역전된다. 이를 방지하기 위해 priority donation 개념이 생겼다.
🔎 그럼 누가 우선순위를 기부하고, 어떤 쓰레드가 우선순위를 기부 받을까?
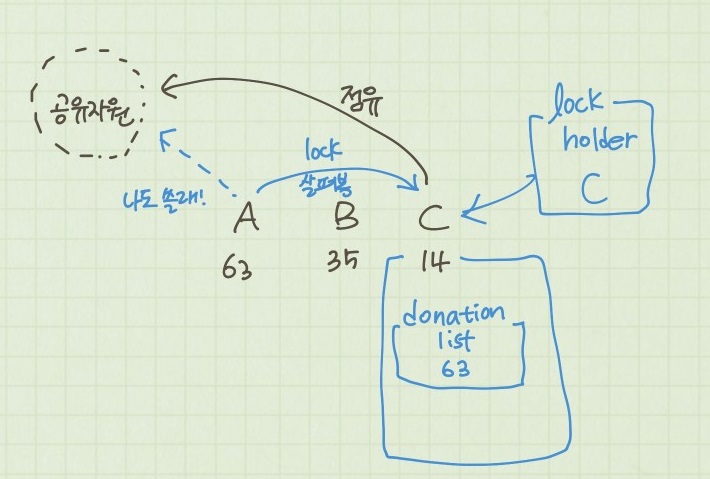
처음 구조체를 살펴 볼때, donation list에는 어떤 값이 들어가야하는지 누가 기부를 받아야하는지 등을 파악하기 쉽지 않았다.
우선순위 기부는 나(A, 63)보다 우선순위가 낮은 thread(C, 14)가 공유자원을 점유하고 있을 때 발생한다.
그렇기 때문에 현재 공유자원을 점유하고 있는 thread(c,14) 내부에 donation list에 네(C,14)가 공유자원을 다 쓰면 내(A, 63)가 쓰겠다고 우선순위를 기부하는 것이다. 수시로 lock(현재 공유자원을 쓸 수 있는지)을 살펴보면서 busy waiting하는 것이다.
Multiple Donation
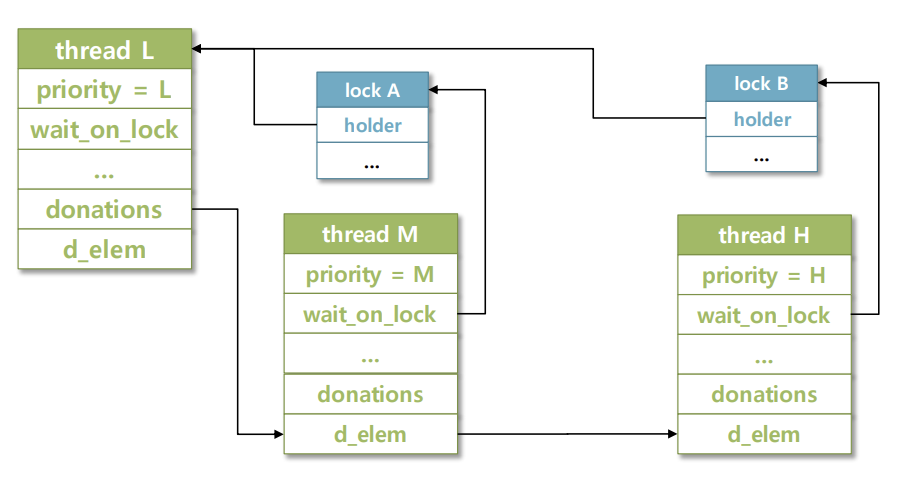
현재 공유자원을 쓰고 있는 L이 공유자원을 반납하기를 M과 H가 기다리고 있다.
thread L의 donations에는 M과 H의 우선순위 정보가 들어있을 것이다.
즉, 동일한 lock을 살펴보는 여러 쓰레드가 있는 상태를 의미한다.
임계영역을 관리하는 공유자원을 여러 쓰레드가 사용하기 위해 대기하고 있는 상태!
Nested Donation
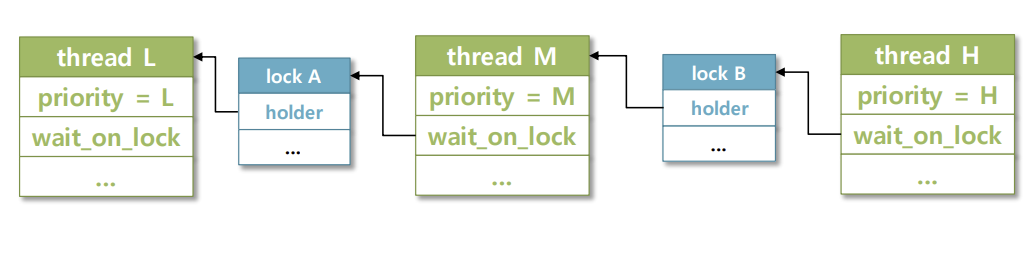
중첩기부, 스레드가 잠금을 기다리고 있는 thread에 우선 순위를 기부하고 대기 중인 스레드가 다른 스레드가 기다리고 있는 다른 잠금을 보유한 상태를 의미한다.
H 쓰레드의 우선순위는 M 쓰레드를 통해 L 쓰레드에 내포됩니다. 이러한 상황은 최악의 경우 교착상태가 되어 효율적으로 자원을 관리할 수 없게 됩니다. 이를 방지하기 위해 nested donation depth를 설정해줘야 합니다.
이번 pintos 과제에서는 이를 8로 설정하라고 가이드라인을 줬기 때문에 8로 설정!
📄 thread.c
void donate_priority(void)
{
/* priority donation 을 수행하는 함수글 구현한다.
현재 스레드가 기다리고 있는 lock과 연결된 모든 스레드들을 순회하며
현재 스레드의 우서순위가 lock을 보유하고 있는 스레드에게 기부한다.
Nested donation 그림 참고, nested depth는 8로 제한다. */
struct thread *curr = thread_current();
int cur_priority = curr->priority;
for (int i=0; i <8; i++)
{
if (curr->wait_on_lock == NULL)
{
break;
}
curr = curr->wait_on_lock->holder;
curr->priority = cur_priority;
}
}nested donation depth는 딱 정해진 숫자로 설정하는 것이 아니라, OS가 무엇인지 어떤 작업을 하는지에 따라 달라지는 값이라고 합니다. pintos과제에서 역시 depth을 8이 아닌 2로 설정해도 test가 통과되는 걸 확인할 수 있었다.
test 결과
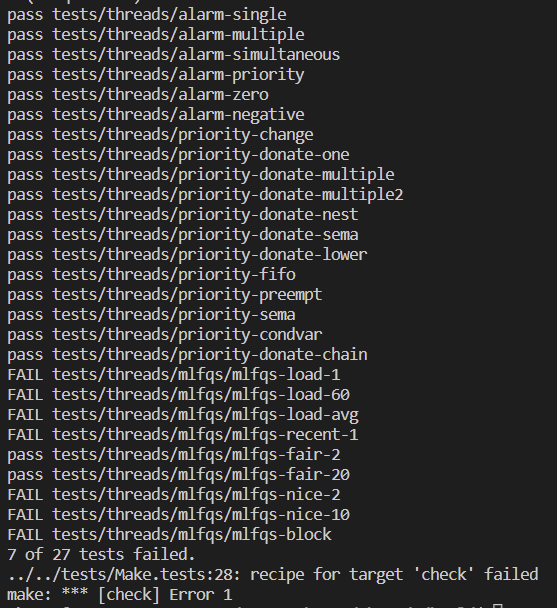
'CS(ComputerScience) > Pintos' 카테고리의 다른 글
| Pintos Project, VScode Debugging Setting (0) | 2023.05.17 |
|---|---|
| Pintos, MM & Anon Page (feat. Page Fault Handling) (0) | 2023.05.16 |
| Pintos Project2. User Program (0) | 2023.05.09 |
| Pintos Alam Clock (0) | 2023.04.24 |



