Pintos Alam Clock
1초당 tick이 100번 돈다는 의미이다. 즉 1 tick은 100분의 1초(10ms).
시스템이 특정 시간에 작업이나 이벤트를 예약할 수 있도록 하는 기능!
활동을 관리하고 조정하여 적정한 시간에 적절한 순서로 발생하도록 전산자원을 관리하는데 사용.
- 시스템(백그라운드 작업, 바이러스 검사, 소프트웨어 fetch 업데이트 예약
- 중요한 이벤트나 기한에 대한 알림 또는 경고(작업을 놓치거나 간과할 가능성 ↓)
- 사용자에게 안정적이고 효과적인 일정 도구를 제공함.
🔎 컴퓨터에서 기계 명령을 어떻게 실행할까?
1. Fetch : 메모리에서 명령어를 가져와서 CPU의 명령어 레지스터(IR, instruction register)에 로드
2. Decode : 수행할 작업과 사용할 피연산자(데이터)를 결정하기 위해 멸령을 디코딩
3. Execute : 피연산자에 명령어에 지정된 연산을 수행하여 명령어를 실행
4. Store : 연산 결과가 메모리 또는 레지스터에 저장.
🔎 System Call (User mode → Kernel mode)

사용자 모드(User mode)에서 커널 모드(Kernel Mode)로 추상화된 파일을 전송할 때 사용.
사용자 프로세스가 파일에 엑세스하려고 하면 먼저, 운영체제에 시스템 호출 요청(이름, 위치 및 엑세스 권한)을 보낸다. 운영체제는 프로세스를 대신하여 요청된 파일 작업을 수행하기 위해 프로세스를 사용자모드에서 커널 모드로 전환해 파일 작업을 수행한다. 안전하고 제어된 방식으로 파일 작업을 수행할 수 있도록 하는 메커니즘이다. 운영체제는 파일 작업을 추상화함으로써 파일 엑세스를 일관되게 할 수 있고 안전한 인터페이스를 제공할 수 있다.
🔎 Interrupt(Kernel mode → H/W mode)
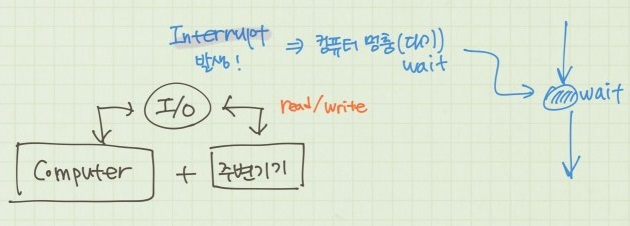
커널모드(Kernel Mode)에서 하드웨어 모드(H/W Mode)로 전환하는 과정에서 발생
키보드 입력 또는 디스크 I/O 완료와 같은 하드웨어 이벤트가 발생하면 하드웨어는 CPU에 대한 인터럽트 신호를 생성.
그런 다음 CPU는 인터럽트를 처리하기 위해 현재 프로세스 실행을 일시적으로 중지하고 커널모드로 전환합니다.
운영체제가 시기적절하고 효율적인 방식으로 하드웨어 이벤트에 응답할 수 있도록 하는 메커니즘.
프로세스를 일시적으로 중단하고 커널모드로 전환하므로서 전체 시스템 작동을 방해하지 않고 인터럽트를 처리, 하드웨어 이벤트가 정확하고 효율적으로 처리되도록 해줌.
📄 threads/thread.c
void thread_sleep(int64_t ticks)
{
/* 현재 스레드가 idle 스레드가 아닐 경우
thread의 상태를 Blocked로 바꾸고 깨어나야 할 ticks을 저장,
슬립 큐에 삽입하고, awake 함수가 실행되어야 할 tick값을 update */
...
ASSERT(!intr_context()); // 현재 인터럽트 컨테스트에서 실행되고 있는지 여부 확인(False 반환되면 프로그램 실행 중지..)
old_level = intr_disable();
/* (비활성화 일 때) 현재 스레드를 슬립 큐에 삽입한 후에 스케줄한다. */
curr->wakeup_tick = ticks;
...
intr_set_level(old_level); // 인터럽트 우선순위 설정
}
inter_disable()인터럽트를 비활성화해 하드웨어 이벤트 또는 소프트웨어 인터럽트에 응답할 수 없도록해 운영체제 중단없이 중요한 작업을 수행. 가능한 짧은 시간 동안만 수행해야 한다. 대부분의 경우 세마포어, 잠금 또는 기타 형태의 프로세스 간 통신과 같은 동기화 기술을 사용하여 인터럽트를 비활성화함.
Pintos에서는 디버깅용으로 사용되었다.
Thread ( Kernel mode )
@/include/lib/kernal/list.h
/* List element. */
struct list_elem {
struct list_elem *prev; /* Previous list element. */
struct list_elem *next; /* Next list element. */
};
/* List. */
struct list {
struct list_elem head; /* List head. */
struct list_elem tail; /* List tail. */
};
📄 threads/thread.h

struct thread {
/* Owned by thread.c. */
tid_t tid; /* Thread identifier. */
enum thread_status status; /* Thread state(runing, waiting, blocked). */
char name[16]; /* 쓰레드 Name 포함 문자 배열 (for debugging purposes). */
int priority; /* Priority. 우선순위 */
/* Shared between thread.c and synch.c. */
struct list_elem elem; /* List element. 목록에서 스레드를 추적하는데 사용하는 목록 요소 */
#ifdef USERPROG
/* Owned by userprog/process.c. */
uint64_t *pml4; /* Page map level 4 데이터 구조에 대한 포인터 */
#endif
#ifdef VM
/* Table for whole virtual memory owned by thread. */
struct supplemental_page_table spt; /* 스레드의 가상 메모리에 대한 추가 페이지 테이블 */
#endif
/* Owned by thread.c. */
struct intr_frame tf; /* Information for switching 스레드 간 전환에 필요한 정보를 저장하는 데 사용하는 데이터 구조*/
unsigned magic; /* Detects stack overflow. 스택 오버플로 감지하는데 사용하는 부호 없는 정수*/
};priority : 스케듈링시, 사용
thread_status status : ready, running, blocked
list_elem elem : 쓰레드 식별자로 추적
🔎 왜 쓰레드는 4kB일까?

가상주소는 32bit long의 고유한 주소값을 가진다.
32bit 각 bit마다 0,1을 가질 수 있으므로 강상주소의 경우의 수는 2^32개가 된다.
다른 말로 가상주소를 사용해 지정할 수 있는 최대 가상공간은 2^32Byte(4GB)라는 소리다.
즉, 컴퓨터에서 실행되는 모든 프로그램은 가상주소를 사용하여 최대 4GB의 메모리에 Access가능하다는 의미!
운영체제에서 가상 메모리를 관리하는 일반적인 기술 중 하나로, 가상 주소 공간을 크기가 4kB인 고정 크기 Page로 나누는 것!
프로세스 또는 스레드가 가상 메모리 주소에 액세스하면 운영 체제는 페이지 테이블을 사용하여 가상 주소를 물리적 주소로 변환한 다음 물리적 메모리 위치에 액세스한다. 가상 메모리를 사용함으로써 운영 체제는 물리적 메모리가 여러 프로세스와 스레드 간에 공유되더라도 각 프로세스나 스레드에 자체 개인 주소 공간이 있다는 환상을 줄 수 있습니다.
즉, 4GB를 4kB의 페이지 단위로 나눠 매핑해주는 작업을 통해 가상메모리를 관리합니다.
/* A kernel thread or user process.
*
* Each thread structure is stored in its own 4 kB page. The
* thread structure itself sits at the very bottom of the page
* (at offset 0). The rest of the page is reserved for the
* thread's kernel stack, which grows downward from the top of
* the page (at offset 4 kB). Here's an illustration:
*
* 4 kB +---------------------------------+
* | kernel stack |
* | | |
* | | |
* | V |
* | grows downward |
* | |
* | |
* | |
* | |
* | |
* | |
* | |
* | |
* +---------------------------------+
* | magic |
* | intr_frame |
* | : |
* | : |
* | name |
* | status |
* 0 kB +---------------------------------+
*
* The upshot of this is twofold:
*
* 1. First, `struct thread' must not be allowed to grow too
* big. If it does, then there will not be enough room for
* the kernel stack. Our base `struct thread' is only a
* few bytes in size. It probably should stay well under 1
* kB.
*
* 2. Second, kernel stacks must not be allowed to grow too
* large. If a stack overflows, it will corrupt the thread
* state. Thus, kernel functions should not allocate large
* structures or arrays as non-static local variables. Use
* dynamic allocation with malloc() or palloc_get_page()
* instead.
*
* The first symptom of either of these problems will probably be
* an assertion failure in thread_current(), which checks that
* the `magic' member of the running thread's `struct thread' is
* set to THREAD_MAGIC. Stack overflow will normally change this
* value, triggering the assertion. */
/* The `elem' member has a dual purpose. It can be an element in
* the run queue (thread.c), or it can be an element in a
* semaphore wait list (synch.c). It can be used these two ways
* only because they are mutually exclusive: only a thread in the
* ready state is on the run queue, whereas only a thread in the
* blocked state is on a semaphore wait list. */Busy - Waiting 방식
thread 상태 : Running, Ready
Runnig --- sleep ---> Ready
Ready --- awake ---> Runnigtimer_interrupt() 함수에서 시스템 clock interrupt를 주기적으로 호출해 ticks 카운터를 증가시키고 wait queue를 확인하여 예약된 스레드를 깨운 뒤, wait queue에서 제거. CPU 주도권을 잡아 코드를 매 줄 실행시킬 때마다 확인하는 방식!
유효하지 않은 작업도 모두 ready list에 담겨져 있는 것!
📄 devices/timer.c
void
timer_sleep (int64_t ticks) {
int64_t start = timer_ticks ();
ASSERT (intr_get_level () == INTR_ON);
while (timer_elapsed (start) < ticks)
thread_yield();
}루프에서 조건을 반복적으로 확인해 유효한 작업 이 아닌데도 불구하고 Thread가 지속적으로 CPU를 사용함.
Using Synchronization Primitives like semaphores or mutexes

Runnig --- sleep(lock) ---> Blocked --- awake(unlock) ---> Readyblocked 처리해 유효하지 않은 스레드는 readylist에 포함시키지 않는다. 스레드가 실행을 재개하기 전에 특정시간이 경과할 때까지 차단하고 대기할 수 있는 절전 기능을 구현한 셈! 리소스를 기다리는 동안 CPU 주기를 낭비할 필요 없게 된다.
차단된 스레드(blocked)는 현재 사용할 수 없는 리소스를 기다리고 있기 때문에 진행할 수 없는 상황을 나타낸다. 스레드가 차단된 동안 CPU 리소스를 소비하지 않으므로 다른 스레드가 CPU를 사용할 수 있다. 전체 시스템 성능을 향상시키기 때문에 빠른 대기보다 더욱 효율적.
test 결과
$ make check
$ cd threads
$ cd build
(threads/build) 폴더 들어온 상태에서
$ pintos -- -q run alarm-multiple
전반적인 함수 동작 이해

thread_yield()는 새로 생성된 thread에게 제어권을 넘김.
현재 thread는 ready로 이동해 새로 생성된 thread가 먼저 선점하도록 제어권을 넘김.
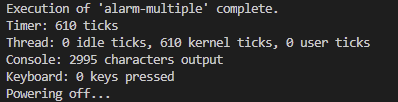
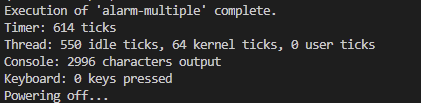
🔎 idle ticks의 의미
CPU가 thread를 실행하지 않고 대부분의 시간을 대기 상태로 있었다는 의미.
즉, thread를 실행하지 않은 시간.
🔎 THREAD_BLOCKED
thread 잠금이 사용가능해진거나 일정 시간이 경과하는 등의 이벤트가 발생하기를 기다리는 상태
깨어날 시작이 되기 전까지는 스케듈링에 포함하지 않으므로써 CPU 낭비를 줄일 수 있다.
blocking 설정은 일종의 제어권이다! 실행할 자격이 없으면, 실행을 기다리고 있는 것이다.
이벤트가 발생할 때까지 기다리는 작업!
🔎 550 idle ticks의 의미
기존 구현 방식이었던 busy waiting 방식일 때는 유효하지 않은 작업 550 ticks에 관해서도 thread가 지속적으로 CPU를 사용하였다. 즉, 굳이 사용하지 않아도되는 550 ticks 관련해서도 CPU를 사용해 왔다는 뜻이다. 불피요한 작업을 하므로써 CPU를 낭비해 왔다는 의미!
| Busy-Waiting | Semaphores |
| 키보드 및 마우스와 같이 자주 엑세스하지 않는 공유 리소스에 대한 동기화 방법. | 동적 프로그램 실행을 포함한 다양한 context에서 공유 리소스에 대한 엑세스를 관리하는데 사용. 한 프로세스안에 스레드가 여러개 있을 수 있고 그 스레드끼리 자원을 공유해야하는데, 같은 변수를 공유하게 되면 서로 값을 바꾸다가 안 맞는 값을 사용할 수 있음. 그렇기 때문에 세마포어와 같은 보다 복잡한 동기화 방법을 사용해 정교한 동기화 기능을 제공해야 한다. |
'CS(ComputerScience) > Pintos' 카테고리의 다른 글
| Pintos Project, VScode Debugging Setting (0) | 2023.05.17 |
|---|---|
| Pintos, MM & Anon Page (feat. Page Fault Handling) (0) | 2023.05.16 |
| Pintos Project2. User Program (0) | 2023.05.09 |
| Pintos, Priority Scheduling and Synchronization (2) | 2023.04.27 |



