Pintos File System
Block이란?
의미있는 정보를 담아 두는 논리적인 단위
파일 시스템이 필요한 이유?
파일을 새로 생성할 때, 하드 디스크에 빈공간을 생성
파일에 접근하고자 할때, 하드 디스크에 몇번째 주소에 있는지 알아야 엑세스 가능
파일에 특정 권한이 있을 경우에만, 삭제&수정 가능하도록 관리.
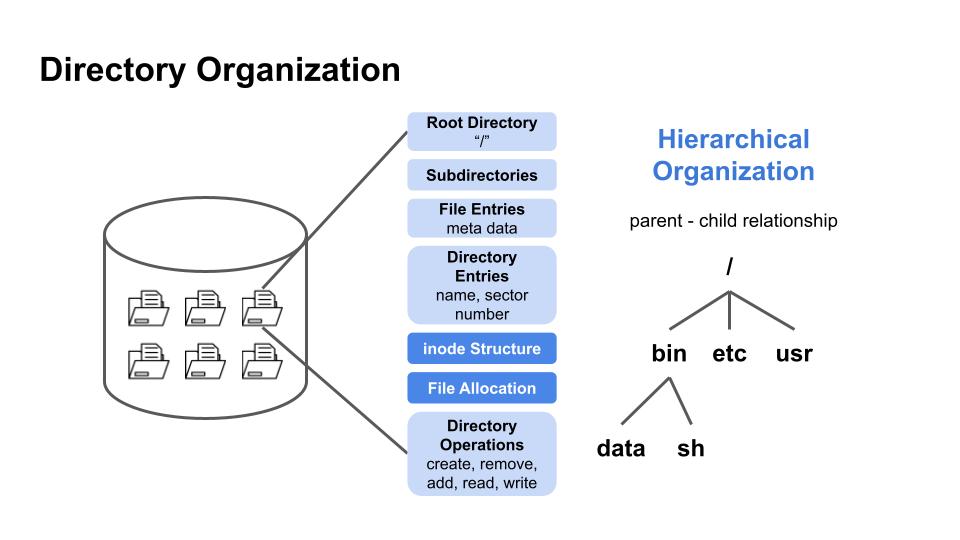
Pintos 의 디렉토리 구성은 계층 구조로 루트 디렉토리와 하위 디렉토리로 구성되어 있습니다. 저희는 파일 시스템 작업의 inode 구조와 파일 할당 등의 디렉토리 구성요소에 집중하여 공부해봤습니다.
먼저 말씀드리고 싶은 것은 파일 시스템에서 디렉토리 입니다.
디렉토리 구조는 계층적인 구조를 통해 하위 디렉토리와 파일을 포함할 수 있는 부모-자식 관계를 만듭니다. 여기서 루트 디렉토리는 디렉토리의 시작점역할을 합니다. 디렉토리는 파일이름과 inode 번호의 쌍으로 구성된 목록이며, 이를 코드상으로 구현해야 하기 때문에 특수한 파일형태로 관리됩니다. 이러한 구조로 디렉토리는 기존 디렉토리 내에 생성되어 중첩 또는 계층 구조를 형성할 수 있습니다.
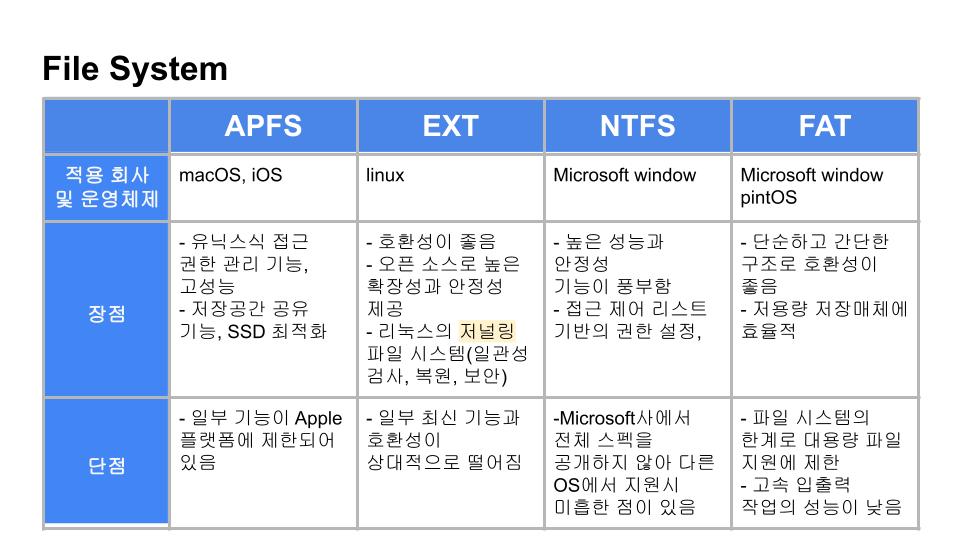
파일시스템은 컴퓨터에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체계입니다.
파일시스템에는 매우 방대한 종류가 있기 때문에, 저희 조는 대표적인 컴퓨터 제조 회사들이 채택하고 있는 파일 시스템들의 특징을 간략히 비교해보았습니다.
APFS는 우리가 사랑하는 맥 OS에서 사용하며, EXT는 호환성이 좋고, 저널링 파일 시스템으로 일관성 검사를 지원합니다.
NTFS 와 FAT은 마이크로 소프트에서 사용하고 있습니다.
NTFS는 서버 관리용으로 제작되었기 때문에 기능이 풍부한 대신, 구현 방식이 공개되지 않아 다른 OS에서 지원에 미흡한 점이 있고고, FAT는 단순하고 간단한 구조로 여러 저용량 저장매체에 널리 사용되고 있습니다.
현재 우리가 핀토스에서 구현한 방식은 이 중 가장 구조가 단순한 FAT로, 다음장에서 추가로 설명하겠습니다.
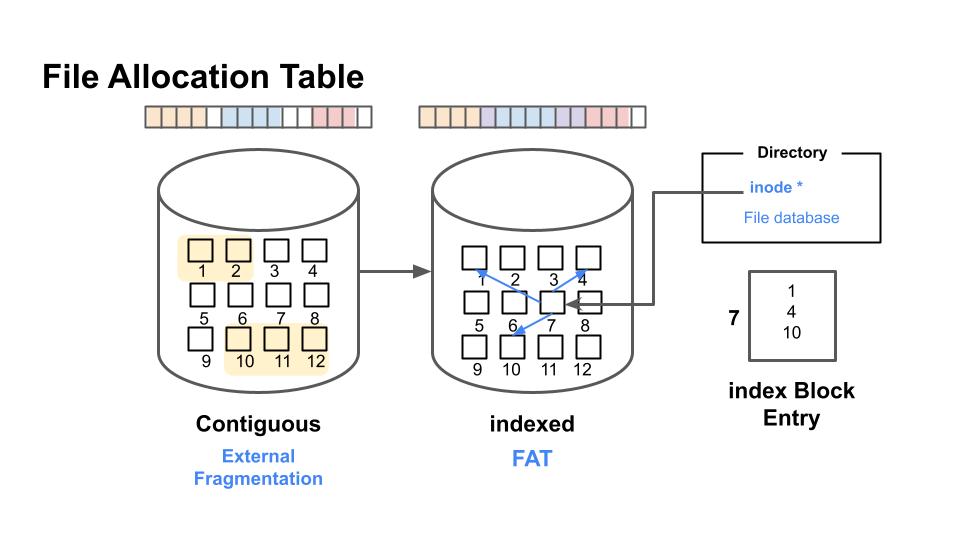
전통적으로 사용하는 연속할당 방법은 파일을 섹터 단위로 나누어 근접한 블록끼리 연속으로 구성되어 파일을 저장합니다.
파일을 섹터 단위로 나누어 연속 저장하게 되면, 파일 크기가 동일하지 않으므로 외부조각이 생기고, 비어있는 공간이 있음에도 활용하지 못하는 외부 단편화 문제가 생깁니다. 하지만 FAT 기반 시스템으로 구현하면 index(inode)기반으로 메타데이터에 직접 접근이 가능하기 때문에 외부조각이 발생하지 않고 효율적으로 파일을 관리할 수 있습니다.
FAT 기반 파일 시스템들은 파일 시스템 내부의 모든 클러스터 하나하나에 대한 항목을 FAT 테이블에서 관리합니다. FAT 테이블은 하나의 단일 리스트(배열)로 관리되며, 이 테이블을 통해 어떤 클러스터가 어떤 파일에서 사용되는지, 혹은 어떤 디렉토리가 존재하는지 등을 알 수 있습니다.
장점
- 새로운 파일을 만들기가 쉽다. 부모 디렉토리 테이블과 FAT의 Busy 필드 내용만 수정하면 된다.
- 파일의 크기를 키우는 것도 쉽다. FAT의 Next 필드만 수정해주면 된다.
- 공간 활용성도 높아진다. 파일을 섹터 단위로 쪼개어 활용할 수 있어서 외부 단편화를 예방할 수 있다.
- 막 그렇게 빠르진 않더라도 Random Access가 가능하다.
단점
- 모든 디스크 블록들이 각각 하나의 FAT 항목을 가지고 있으므로, 만약 굉장히 용량이 큰 디스크의 경우에는 FAT의 크기도 굉장히 커질 수 있다.
- 이를 막기 위해서 블록 하나의 크기를 키울 수 있지만, 그렇게 되면 내부 단편화가 심해질 수 있다.
inode 구조체를 활용해 직접 접근하는 방식은 다음 장에서 자세히 설명하도록 하겠습니다.
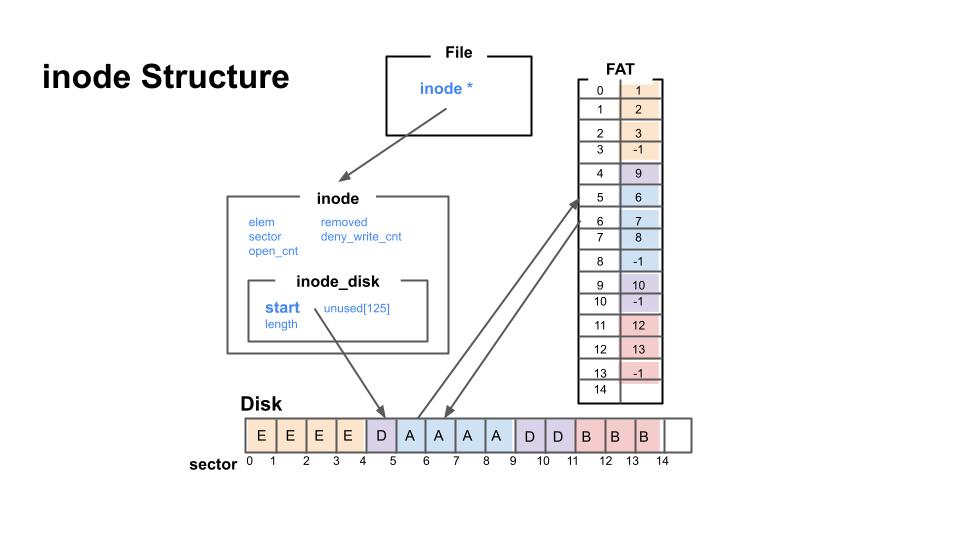
inode는 index node의 줄임말로, 파일이나 디렉토리의 메타데이터를 갖는 고유 식별자입니다.
파일과 디렉토리는 모두 inode를 하나씩 가리키는 inode 포인터를 가지고 있는데, 이전 프로젝트에서 우리가 다뤘던 struct file과, struct dir 구조체에 바로 이 inode 포인터가 포함되어 있습니다. 따라서, 파일이나 디렉토리를 열 때 inode_open 함수가 실행됨과 동시에 inode 구조체가 생성되게 됩니다.
그림을 보시면, inode 구조체 안에 메타데이터 정보를 담고 있는 inode_disk가 포함되어 있고, inode_disk에는 실제 파일에 대한 데이터가 들어있는 것을 알 수 있습니다. inode_disk는 파일이 열리지 않았을 땐 디스크 영역 섹터에 저장되어 있다가, inode open 함수가 실행될 때 디스크에서 복사되어 인코어(incore) inode로 메인 메모리에 올라갑니다.
inode_open 이 작동하는 방식을 조금 더 살펴보겠습니다.
1. 열려있는 아이노드를 리스트로 관리함.
2. 이 리스트를 돌면서 아이노드가 열려있는지 확인하고, 열려있다면 inode_reopen 함수를 호출해, 해당 아이노드를 open한 횟수를 1 늘려줌
3. incore inode를 위한 메모리 공간을을 할당(malloc)
4. 리스트에 아이노드를 삽입하고, 필드들을 초기화 한 뒤, 디스크에서 disk_inode 정보를 읽어옴
struct inode_disk
- start : 첫 번째 데이터 섹터의 섹터 번호
- length : 바이트 단위의 파일 크기
- magic : 확인 또는 식별 목적
- unused : 배열
struct inode
- elem : 목록에서 아이노드를 유지하기 위해 사용되는 요소
- sector : inode가 저장되는 디스크 위치의 섹터 번호
- open_cnt : inode를 연 프로세스 또는 스레드의 수
- removed : inode가 삭제되었는지 여부를 나타내는 플래그
- deny_write_cnt : 현재 inode에 대한 쓰기를 거부하는 프로세스 또는 쓰레드 수

@@ filesys/page_cache.c
블록 수준 캐싱(페이지 수준 캐싱)
데이터가 기록될 때 먼저 페이지 캐시에 기록되고 나중에 더 큰 chunk 또는 특정 동기화 지점과 같은 보다 효율적인 방식으로 디스크에 flush 됨. 버퍼 캐시는 파일 시스템과 디스크 사이의 중간 계층 역할을 하여 디스크 I/O 요청을 가로채고 자주 엑세스하는 블록에 대한 빠른 엑세스 제공함.
섹터 수준 캐싱
디스크 엑세스 최적화, 자주 엑세스하는 섹터에 대한 디스크 읽기 및 쓰기 빈도를 줄여 전반적인 성능을 향상시킴.
Pintos 파일 시스템은 write-back 또는 write-through 정책과 같은 전략을 사용하여 캐시 일관성을 관리하고 무결성을 보장합니다. 이 두가지 캐싱 방식을 이용해 디스크 엑세스를 줄임으로써 성능을 향상시키고 디스크 I/O 작업의 빈도를 줄이고 파일 읽기 및 쓰기 작업의 전반적인 효율성을 향상시킵니다.
MSI 프로토콜이란?
Modified, Shared, Invalid 프로토콜
다중 캐시 시스템에서 여러개의 캐시가 동일한 데이터를 가지고 있을 때, 발생 할 수 있는 불일치 문제를 해결하기 위해 가장 기본적인 프로토콜
Shared 상태
가장 기본 상태로, 동기화가 완료된 직후나 값에 변함이 없는 상태
Modified 상태
코어가 캐시 및 메모리 값을 바꾸려고 할때 "나는 수정중이야" 라는 상태를 알려 다른 코어의 요구를 거부합니다.
Invalid 상태
캐시 라인의 상태가 유효하지 않다는 의미, 새롭게 데이터를 쓰려는 코어가 본인의 라인을 제외한 다른 캐시라인들의 상태를 전부 I상태로 바꾸어 놓습니다.
"나는 데이터를 수정중이고 너희 캐시에 있는 데이터는 유효하지 않아" M상태로 만든 코어가 모든 코어에게 경고하는 것.
write-back 정책이란?
데이터가 메모리와 동시에 캐시에 쓰여지는 정책으로 캐시와 메모리의 데이터는 항상 일관된 상태를 유지합니다. MSI 프로토콜에서는 Modified 상태에서 데이터가 캐시와 메모리에 동시에 쓰여지도록 write-through 정책을 사용할 수 있습니다.
write-through 정책이란?
데이터의 변경이 발생했을 때 해당 데이터를 먼저 캐시에만 업데이트하고 나중에 변경된 데이터를 메모리로 쓰는 정책으로 데이터의 쓰기는 캐시에만 이루어지기 때문에 쓰기 연산 속도가 빠르며, 데이터가 메모리로 쓰여질 때까지는 메모리와 캐시의 데이터가 불일치 상태가 됩니다. MSI 프로토콜에서는 Modified 상태의 데이터가 변경되면 캐시에만 업데이트되고, 해당 블록은 Exclusive 상태로 변경됩니다. 나중에 해당 블록이 캐시에서 내려갈 때(Modified에서 Invalid로 변경될 때) 변경된 데이터가 메모리로 쓰여집니다.
디스크 엑세스와 관련된 대기 시간을 줄여 파일 시스템 성능이 빨라져 Buffer Cache를
왜 512byte로 sector 크기 했냐? (block단위 관리 이유)
디스크 스토리지에 실용적이고 광범위하게 지원되는 구성을 제공하기 위해 역사적인 선례, 하드웨어 호환성, 성능 고려 사항, 상호 운용성 및 단순화된 구현을 결합합니다.
byte 단위로 하면 관리하는 사이즈도 그만큼 듦, 메모리 2배!
그래서 블록단위로 관리. 관리용 데이터 저장 공간도 필요…
meta data에 어떤 값이 있냐?
파일 크기, 파일 유형 및 권한, 데이터 블록에 대한 포인터,
타임스탬프, 파일 소유권, 파일 링크(inode를 가리키는 여러 디렉토리 항목) → 파일의 수명을 관리하고 정리하는데 도움이 됨. 즉, 파일 생성, 삭제, 수정 및 엑세스 제어와 같은 파일 작업을 효율적으로 관리할 수 있도록 하는 역할…
symbolic link란?
hard link란?
'CS(ComputerScience)' 카테고리의 다른 글
| Pintos, Virtual Memory (0) | 2023.05.23 |
|---|---|
| tiny 웹서버 구현 (0) | 2023.04.19 |
| Network, 통신 Model (0) | 2023.04.19 |
| 명시적 가용 리스트 Explicit Free List (0) | 2023.04.13 |
| 묵시적 가용 리스트 Implicit Free List (1) | 2023.04.12 |



