묵시적 가용 리스트 Implicit Free List
명시적 메모리 할당없이 구조 내부 암시적 요소(Graph, Tree자료구조, header & footer) 이용해 가용블록 탐색

일반적으로 가용 블록 탐색에 선형 시간(linear time)이 필요.
각 블록의 헤더를 순서대로 탐색해야 하므로 목록의 크기에 비례해 선형시간이 걸리게 됨.
그렇기 때문에 메모리 크기가 크면 클수록 탐색 시간이 길어진다.
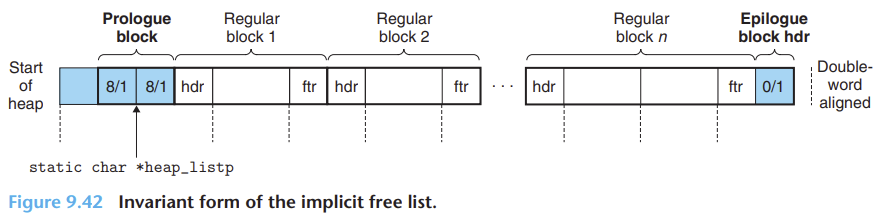
Unused : padding
8/0 : Prologue Header
8/0 : Prologue Footer
0/1 : Epilogue Header
heap_listp는 proloue header와 prologue footer 사이에 위치헤 payload를 가리키도록 설정해준다.
왜냐하면, 할당하고자 하는 사이즈보다 큰 가용블록이 없을 경우 가용블록을 만들어줘야 하기 때문!
📄 mm.c
int mm_init(void)
{
...
PUT(heap_listp, 0); // Alignment padding
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); // Prologue header
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); // Prologue footer
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); // Epilogue header
heap_listp += (2*WSIZE); // payload pointer
...
}implicit free block 할당, 해제 할때 주의할 점
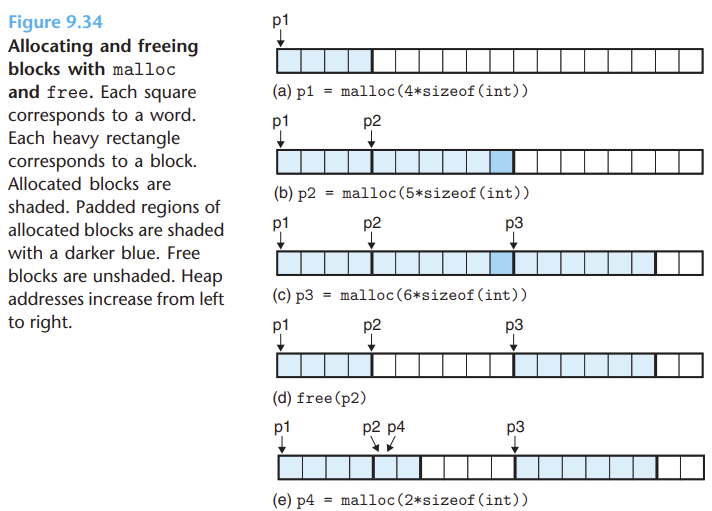

🔎 Padding
데이터를 블록의 크기에 맞추기 위해 추가되 비트나 바이트
메모리 할당을 보다 효율적으로 하기 위해 할당할 크기가 Word Size의 배수가 되도록 해준다.
패딩은 데이터의 크기를 일정한 크기로 맞추는 목적으로 사용되므로 패딩의 크기는 다를 수 있다.
즉, Padding은 데이터를 블록 단위로 처리하기 위해 사용되는 추가적인 비트나 바이트 입니다.
📌 일반적인 메모리의 정렬 기준
- 32bit System : 4byte
- 64bit System : 8bye
메모리의 크기는 하드웨어나 운영체제의 설계 지침에 따라 다르게 설정.
🔎 메모리 정렬을 하는 이유?
CPU와 RAM은 거리가 멀어 접근 횟수가 많아질 수록 속도가 느려집니다.
데이터를 한번 가져올 수 있는 크기가 word size 배수일 때 가장 효율적입니다.
또한 CPU의 메모리 컨트롤러(MC) 또는 컨트롤러 유닛(MCU)은 정렬된 값을 읽을 때 곧바로 레지스터에 저장할 수 있습니다. 정렬을 하지 않으면, 쓰레기값을 읽거나 프로그램이 강제 종료되기도 합니다.
📄 mm.c
void *mm_malloc(size_t size)
{
...
/* Adjust block size to include overhead and alignment reqs */
if (size <= DSIZE)
asize = 2*DSIZE; // 8의 배수로 조정
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
...
}
static void *extend_heap(size_t words)
{
...
/* Allocate an even number of words to maintain alignment */
// 정렬을 위해 짝수 갯수의 words 할당.
size = (words % 2) ? (words + 1)*WSIZE : words * WSIZE;
...
}
Fragmentation
메모리를 블록 처리 함으로써 저장 공간이 낭비되는 현상
🔎 Internal fragmentation(내부 단편화)

3 * word size 가 낭비되고 있다.
🔎 External Fragmentation(외부 단편화)
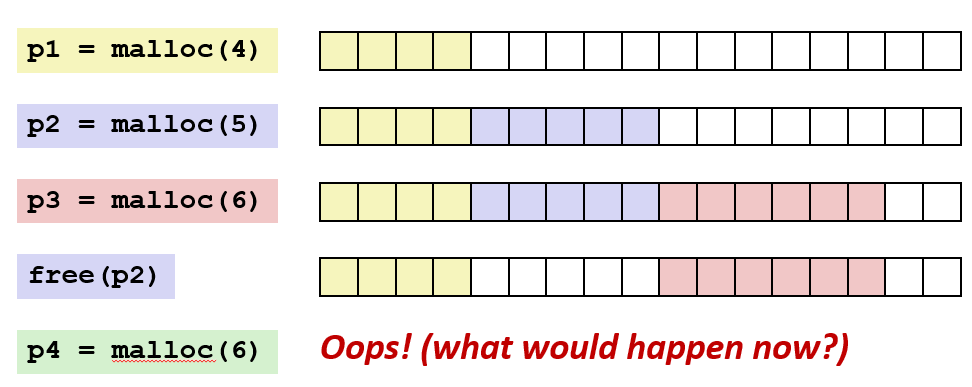
7 * word size의 free block이 있지만, 연속되어 있지 않아 6 * word size의 데이터를 할당할 수 없다.
fragmentation을 최소화하는 방법
🔎 Splitting

2 * word 사이즈의 내부 단편화를 split해 2 * word 사이즈의 free block 처리해 재활용성을 높임.
장점 : 메모리 낭비를 최소화해 내부 단편화를 줄이는데 유용
단점 : 블록을 다시 분리하는 작업이 필요. 메모리 할당 요청이 자주 발생하는 경우 오버헤드 증가.
📄 mm.c
static void place(void *bp, size_t asize)
{
size_t old_size = GET_SIZE(HDRP(bp)); // header에 접근해 free_block 사이즈 반환
size_t remaining = old_size - asize; // 할당 한뒤, 남겨지는 사이즈 splitting
if (remaining >= (2*DSIZE)) {
// splitting
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
char *next_bp = NEXT_BLKP(bp); // free block splitting
PUT(HDRP(next_bp), PACK(remaining, 0));
PUT(FTRP(next_bp), PACK(remaining, 0));
}
...
}
🔎 coalescing

앞 뒤 블록 정보(size, alloc) 활용해 사용가능한 가용블록을 합쳐 외부 단편화를 줄일 수 있다.
장점 : 내부 단편화와 외부 단편화 줄어듦
단점 : 가용블록들이 자주 합쳐지는 경우 메모리 사용을 위해 매번 이 작업을 반복해 비효율적이다.
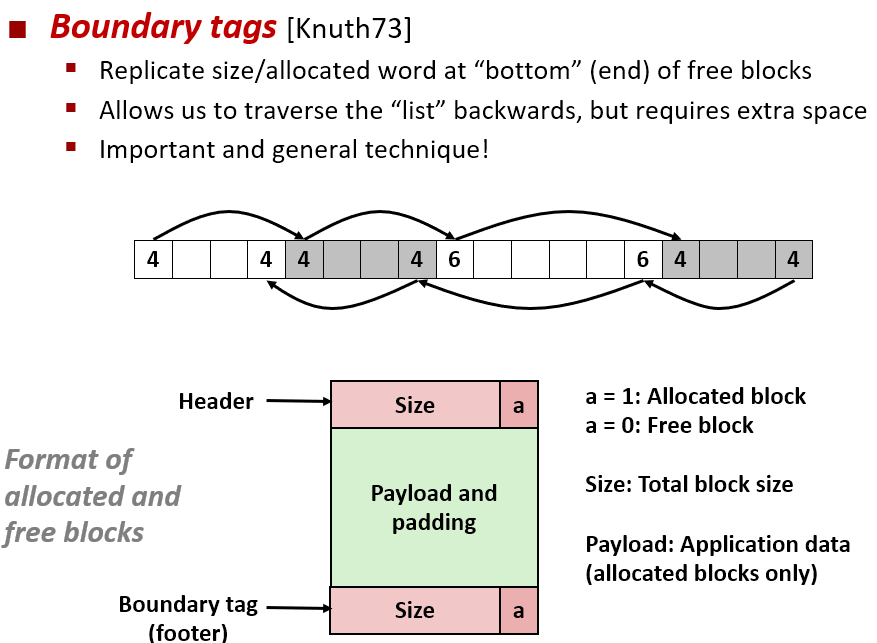
Header 와 Footer을 활용해 더 많은 free block을 탐색해 합칠 수 있음
📄 mm.c
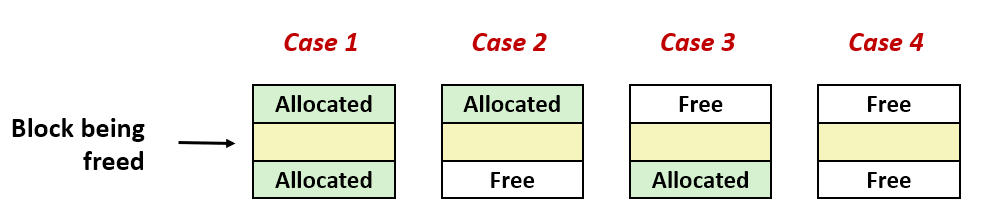
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 이전 블록 footer에 접근해 할당 여부 반환
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 다음 블록 header에 접근해 할당 여부 반환
size_t size = GET_SIZE(HDRP(bp)); // 현재 블록의 header에 접근해 size정보 반환
// Case 1
if (prev_alloc && next_alloc) {
// 이전 블록과 다음 블록 모두 할당되어 있으면 현재 block point 반환
return bp;
}
// Case 2
else if (prev_alloc && !next_alloc) {
// 이전 블록 할당, 다음 블록 free
// 다음 블록 header에 접근
size += GET_SIZE(HDRP(NEXT_BLKP(bp))); // 다음 블록 사이즈 만큼 size 더해줌
// block point는 현재 그대로 유지지
PUT(HDRP(bp), PACK(size, 0)); // 현재 블록의 header 정보 갱신
PUT(FTRP(bp), PACK(size, 0)); // 현재 블록의 footer 정보 갱신
}
// Case 3
else if(!prev_alloc && next_alloc) {
// 이전 블록 free, 다음 블록 할당
// 이전 블록 footer에 접근
size += GET_SIZE(FTRP(PREV_BLKP(bp)));
// block point를 이전 블록의 포인터 위치로 갱신
PUT(FTRP(bp), PACK(size, 0)); // 현재 블록의 footer의 정보 갱신
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록의 header 정보 갱신
bp = PREV_BLKP(bp); // block point를 이전 블록의 block point로 변경
}
// Case 4
else if(!prev_alloc && !next_alloc) {
// 이전 블록 free, 다음 블록 free
// 이전 블록 footer와 다음 블록 header에 접근
size += GET_SIZE(FTRP(PREV_BLKP(bp))) + GET_SIZE(HDRP(NEXT_BLKP(bp)));
// block point를 이전 블록의 포인터 위치로 갱신
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록의 header 정보 갱신
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); // 다음 블록의 fooder 정보 갱신
bp = PREV_BLKP(bp); // block point를 이전 블록의 block point로 변경
}
return bp;
}앞뒤 블록 정보를 활용해 free blcok size와 현재 블록의 payload 가리키는 포인터 위치(bp) 변경해줌!
가용 블록을 탐색하는 방법

First fit : 리스트의 처음부터 검색해 크기가 맞는 첫번째 가용 블록 선택
2023.04.10 - [CS(ComputerScience)] - Memory allocation using implicit free block tracking and first-fit method
Nest fit : find fit 이후 block만 탐색해 탐색 범위를 줄임.
2023.04.10 - [CS(ComputerScience)] - Memory allocation using implicit free block tracking and next-fit method
Best fit : heap의 처음부터 끝까지 모든 블록을 검사해 요청한 할당 크기와 가장 가까운 블록을 찾아 메모리 할당
2023.04.10 - [CS(ComputerScience)] - Memory allocation using implicit free block tracking and best-fit method
공부 자료 : 컴퓨터 시스템 Computer Systems: A Programmer's Perspective by Randal E. Bryant David R. O'Hallaron 9장 가상 메모리
'CS(ComputerScience)' 카테고리의 다른 글
| Network, 통신 Model (0) | 2023.04.19 |
|---|---|
| 명시적 가용 리스트 Explicit Free List (0) | 2023.04.13 |
| 가상 메모리 (0) | 2023.04.12 |
| Memory allocation using explicit free block tracking and first-fit method (0) | 2023.04.11 |
| Memory allocation using implicit free block tracking and best-fit method (0) | 2023.04.10 |



